强化学习笔记
强化学习依赖 GPU 加速训练出离线 Policy;那么基于模型的算法能否用 GPU 实现快速的在线规划算法?
构建并行仿真环境 create_sim
步骤:
- gym.create_sim
- 创建地形
_create_envs- loads the robot URDF/MJCF asset,
- For each environment:
- creates the environment
- calls DOF and Rigid shape properties callbacks
_process_rigid_shape_props_process_dof_props_process_rigid_body_props
- create actor with these properties and add them to the env
- Store indices of different bodies of the robot
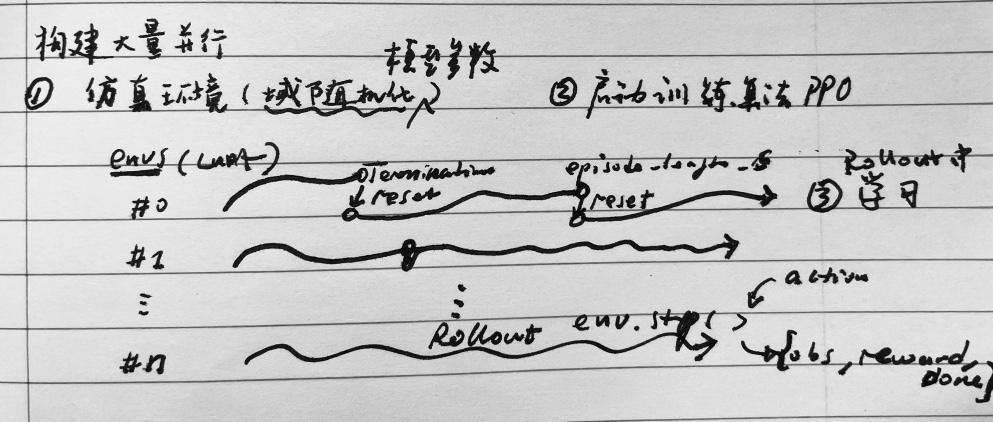
训练算法与环境交互
- PPO. – [actions] –> Envs.step()
- Envs – [obs,reward,reset] –> PPO
实现原理
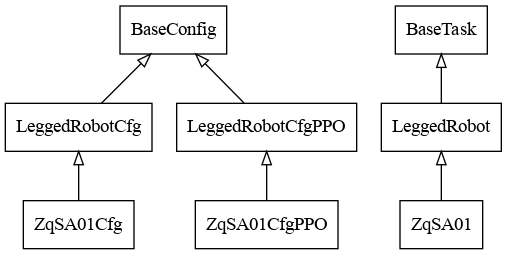
class BaseTask
- get_observations
- get_privileged_observations
- render
- reset 重置所有并行仿真环境
- reset_idx NotImplementedError 重置单个环境
- 更新课程
- 重置机器人状态
- 重新采用指令
- 重置缓存
- 重置重设指令的步态生成器的初始计数值
- 更新观测量缓存
- step NotImplementedError
- PD: Action > Torque
- 物理仿真
gym.simulate(sim) post_physics_step_post_physics_step_callbackcheck_terminationcompute_rewardreset_idxcompute_observations
- 返回 观测量+特权观测量+奖励+重置与否+其他信息
总结来说,正奖励与负奖励的主要区别在于它们对智能体行为的引导方式不同:🏆正奖励 $\exp(-x)$ 鼓励行为重复,⛔负奖励则抑制行为。通过正负奖励的巧妙设计,智能体可以逐步学会最优策略。
class LeggedRobot
- _compute_torques 用 Action + PD 算力矩
- _create_envs 根据 URDF 创建并行仿真环境
- _create_ground_plane
- _create_heightfield
- _create_trimesh
- _draw_debug_vis
- _get_env_origins
- _get_heights
- _get_noise_scale_vec 生成观测量噪声
- _init_buffers 初始化 Tensor 缓存变量
- _init_height_points
- _parse_cfg
- _post_physics_step_callback 指令采样 计算地形高度和外部扰动
- _prepare_reward_function
- _process_dof_props 获取非浮动基关节 Limit 信息
- _process_rigid_body_props 刚体质量 质心 惯量随机化
- _process_rigid_shape_props 摩擦系数随机化
- _push_robots 浮动基速度随机化
- _resample_commands 指令随机化
- _reset_dofs 非浮动基关节位置速度随机化
- _reset_root_states 浮动基位置速度随机化
- _update_terrain_curriculum 更新地形课程
- check_termination 检查每个环境终止条件
- compute_observations override 计算观测量
- compute_reward 计算奖励
- create_sim 构造并行仿真环境
- post_physics_step 检查终止条件 > 计算奖励 > 重置 > 计算观测量
- reset_idx override 重置单个环境
- set_camera
- step override 执行 Action > 物理仿真 > post_physics_step
- update_command_curriculum 更新指令课程
- ⛔ _reward_lin_vel_z 惩罚浮动基重力方向线速度
- ⛔ _reward_ang_vel_xy 惩罚浮动基水平方向角速度
- ⛔ _reward_orientation 惩罚浮动基姿态
- ⛔ _reward_base_height 惩罚浮动基高度
- ⛔ _reward_torques 惩罚关节输出力矩
- ⛔ _reward_dof_vel 惩罚关节速度
- ⛔ _reward_dof_acc 惩罚关节加速度
- ⛔ _reward_action_rate 惩罚 action 变化率
- ⛔ _reward_collision 惩罚所选刚体碰撞
- ⛔ _reward_termination 终止时的奖励
- ⛔ _reward_dof_pos_limits 惩罚关节位置趋近极值
- ⛔ _reward_dof_vel_limits 惩罚关节速度趋近极值
- ⛔ _reward_torque_limits 惩罚关节输出力矩趋近极值
- 🏆 _reward_tracking_lin_vel exp 奖励线速度跟踪
- 🏆 _reward_tracking_ang_vel exp 奖励角速度跟踪
- ⛔ _reward_feet_air_time 奖励足端持久腾空
- ⛔ _reward_stumble 惩罚足端与竖直表面接触
- ⛔ _reward_stand_still 惩罚关节运动(站立时)
- ⛔ _reward_feet_contact_forces 惩罚足端过大的接触力
class ZqSA01
- _get_noise_scale_vec override 生成观测量噪声
- _refresh_gym_tensors 更新仿真器 Tensor
- _resample_commands override 指令随机化
- _reset_dofs override 非浮动基关节位置速度随机化
- _reset_root_states override 浮动基位置速度随机化
- check_termination override 检查每个环境终止条件
- compute_observations override 计算观测量
- compute_reference_states 计算参考状态
- create_sim override 构造并行仿真环境
- reset_idx override 重置单个环境 重置重设指令的步态生成器的初始计数值
- step override 执行 Action > 物理仿真 > post_physics_step
- ⛔ _reward_no_fly 奖励单脚接触
- 🏆 _reward_target_joint_pos_l exp 奖励
- 🏆 _reward_target_joint_pos_r exp 奖励
- 🏆 _reward_orientation exp 奖励
- 🏆 _reward_tracking_lin_x_vel exp 奖励
- 🏆 _reward_tracking_lin_y_vel exp 奖励
- ⛔ _reward_action_smoothness 指令平滑项
- 🏆 _reward_feet_distance exp 奖励双脚保持一定距离
- ⛔ _reward_ankle_action_rate 惩罚
- ⛔ _reward_ankle_dof_acc 惩罚
- 🏆 _reward_target_ankle_pos exp 奖励
- 🏆 _reward_target_hip_roll_pos exp 奖励
参数配置
class LeggedRobotCfg
| XXX | function |
|---|---|
| env | 环境信息 |
| terrian | 地形信息 |
| init_state | 初始状态 |
| control | 关节控制 |
| sim | 仿真参数 |
| viewer | 观察设置 |
| noise | 噪声参数 |
| normalization | 缩放参数 |
| commands | 指令参数 |
| asset | 机器模型 |
| domain_rand | 域随机化 |
| rewards | 奖励参数 |
class LeggedRobotCfgPPO
| XXX | function |
|---|---|
| policy | 策略网络 |
| runner | ActorCritic |
| algorithm | 算法参数 |
训练日志
Learning iteration 20291/40000
Computation: 215205 steps/s (collection: 0.333s, learning 0.124s)
Value function loss: 0.2949
Surrogate loss: -0.0028
Mean action noise std: 0.51
Mean reward: 628.45
Mean episode length: 1985.67
Mean episode rew_action_rate: -1.6791
Mean episode rew_ankle_action_rate: -0.3818
Mean episode rew_ankle_dof_acc: -0.0201
Mean episode rew_collision: -0.0008
Mean episode rew_dof_acc: -0.1378
Mean episode rew_dof_pos_limits: -0.0000
Mean episode rew_feet_contact_forces: -0.2618
Mean episode rew_feet_distance: 0.9603
Mean episode rew_lin_vel_z: -0.0237
Mean episode rew_orientation: 9.7049
Mean episode rew_target_joint_pos_l: 9.0367
Mean episode rew_target_joint_pos_r: 7.1679
Mean episode rew_termination: -0.0000
Mean episode rew_torque_limits: -0.0351
Mean episode rew_torques: -0.1538
Mean episode rew_tracking_ang_vel: 1.7254
Mean episode rew_tracking_lin_x_vel: 3.2664
Mean episode rew_tracking_lin_y_vel: 2.3819