Warp Notes
Features
- Write CUDA kernel in 100% Python syntax
- Runtime JIT compilation
- Rich vector math library
- Mesh processing and queries
- AD
- Interop with PyTorch, JAX
- USD import/export
import warp as wp
@wp.kernel
def integrate(
p: wp.array(dtype=wp.vec3),
v: wp.array(dtype=wp.vec3),
f: wp.array(dtype=wp.vec3),
m: wp.array(dtype=float),
):
# thread id
tid = wp.tid()
# Semi-implicit Euler step
v[tid] = v[tid] + (f[tid] * m[tid] + wp.vec3(0.0, -9.8, 0.0)) * dt
x[tid] = x[tid] + v[tid] * dt
# kernel launch
wp.launch(integrate, dim=1024, inputs=[x, v, f, ...], device="cuda:0")
Python GPU Ecosystem
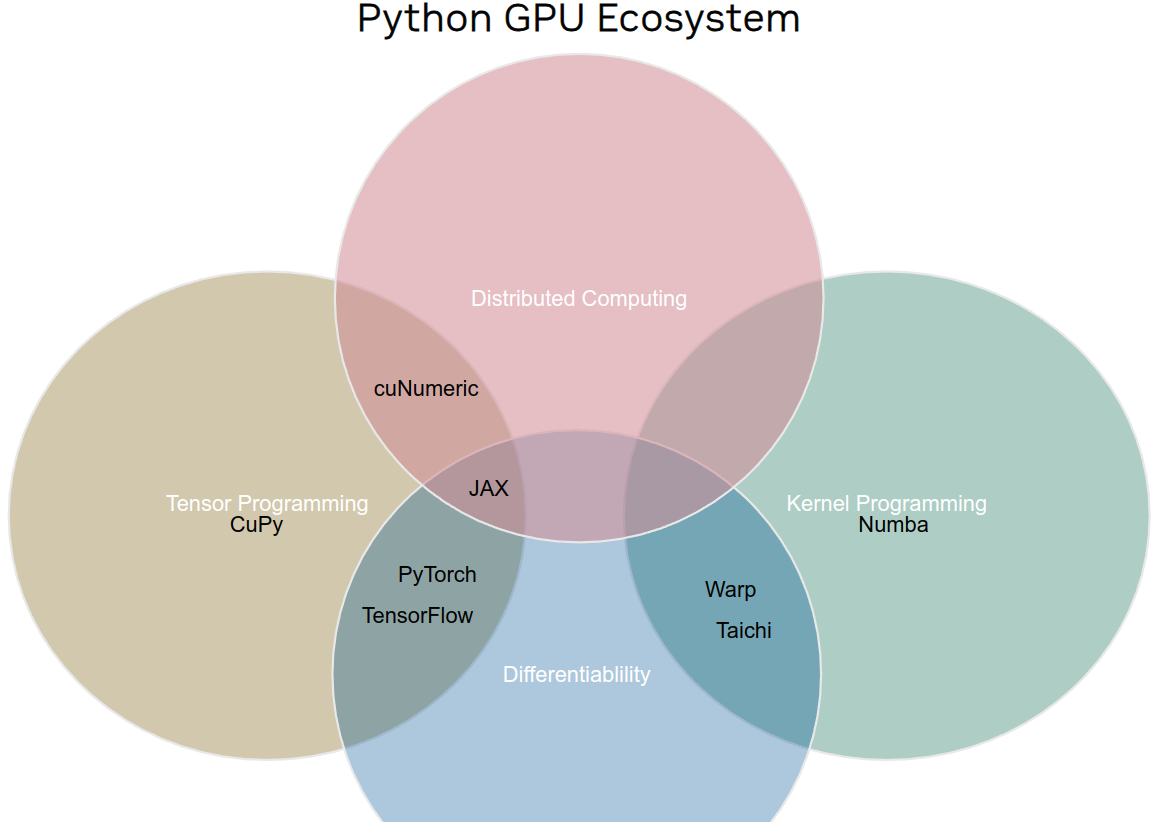
Warp Python Modules
warp.core: math, geometry, vector librarywarp.sim: real-time simulation for robotic control, rigid/soft bodies, particles, cloth, URDF/MJCF/UsdPhysicswarp.fem: PDEwarp.llm
Data Model
- Host/Device memory managed through
wp.arraytype - Builtin spatial math types:
vec2,vec3,vec4,mat22,mat33,mat44,quad,transform - Support for all common array protocols:
__array_interface__,__cuda_array_interface__,__dlpack__ - 0-copy interop with PyTorch, JAX
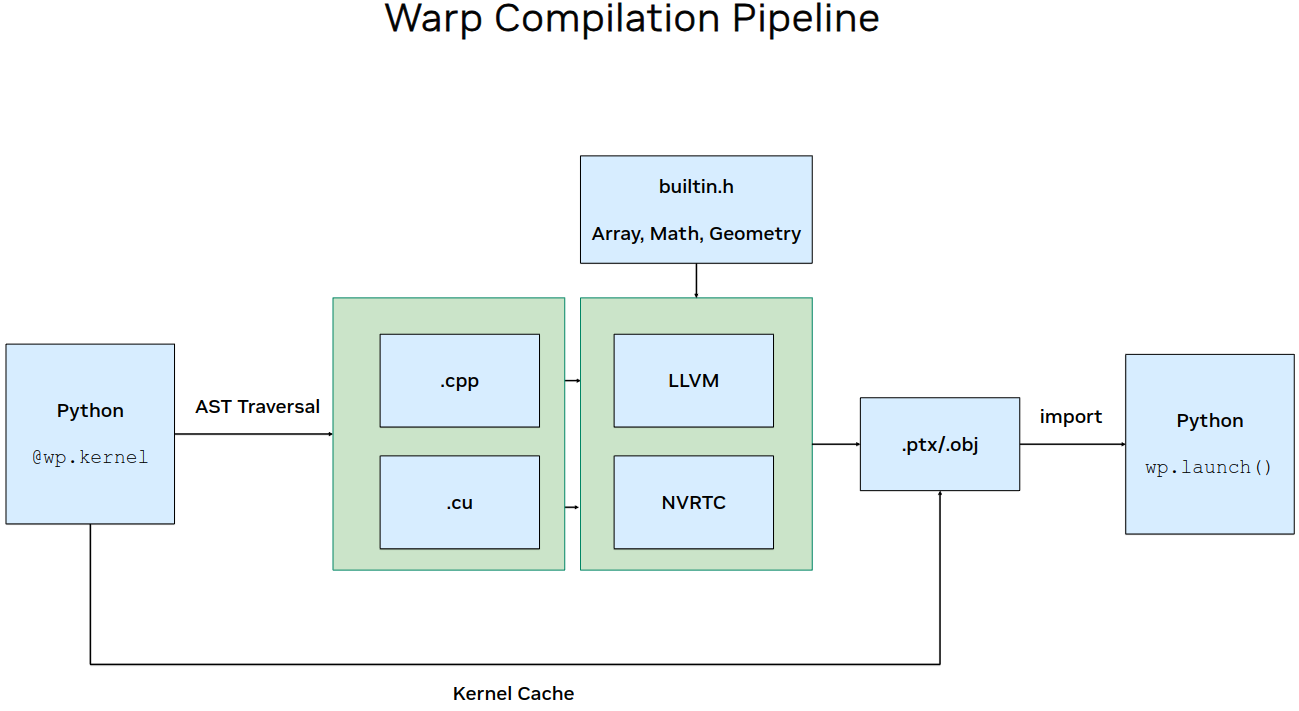
Compilation Pipeline
Execution Model
- Kernels 启动 N 维线程块 (N ≤ 4)
- 纯 SIMT 模型
- No shared memory
- No warp-level primitives
Custom CUDA Code
调用原始 CUDA 代码的好处:
- 能用共享内存
- Fine grained synchronization
- Cooperative operations
AD
Mesh, Hash Grid, Sparse Grid
Warp Sim
Integrators:
- Symplectic Euler (semi-implicit)
- XPBD (implicit)
- Featherstone: which provides more stable simulation of articulated rigid body dynamics in generalized coordinates
- ctypes
- NVRTC (Runtime Compilation)
- NVCC
- PTX (Parallel Thread Execution, IR)
- CUBIN