cuRobo Notes
Cite: https://curobo.org/
cuRobo
CUDA + PyTorch as the front-end + Warp
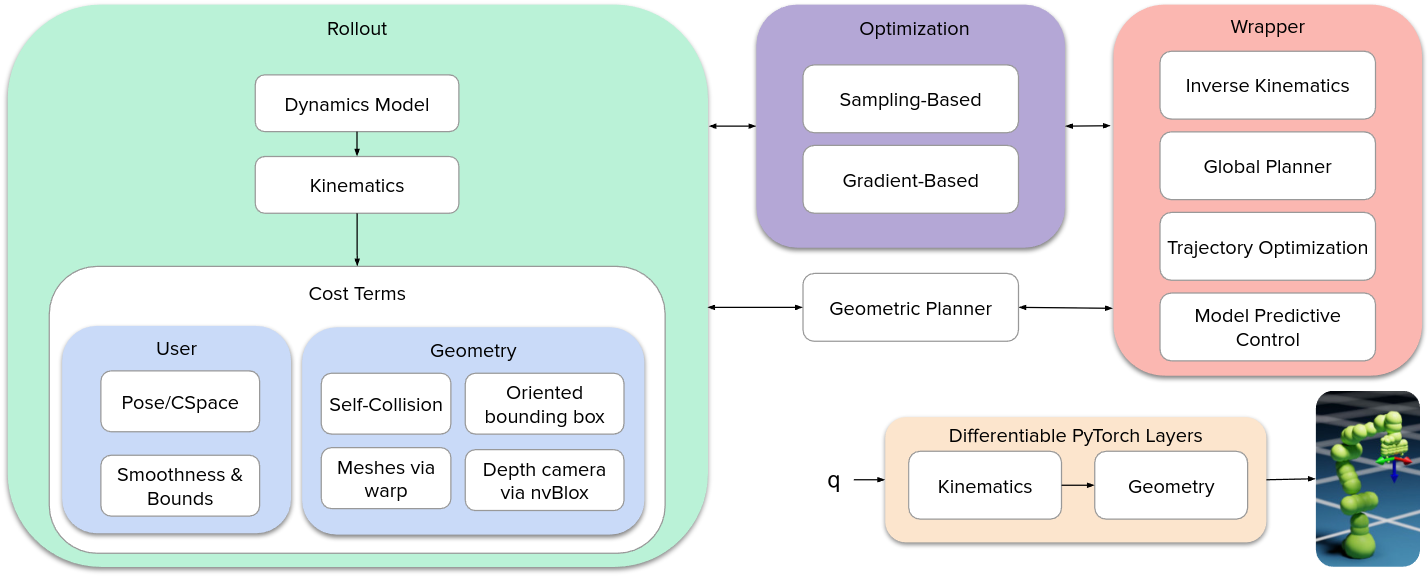
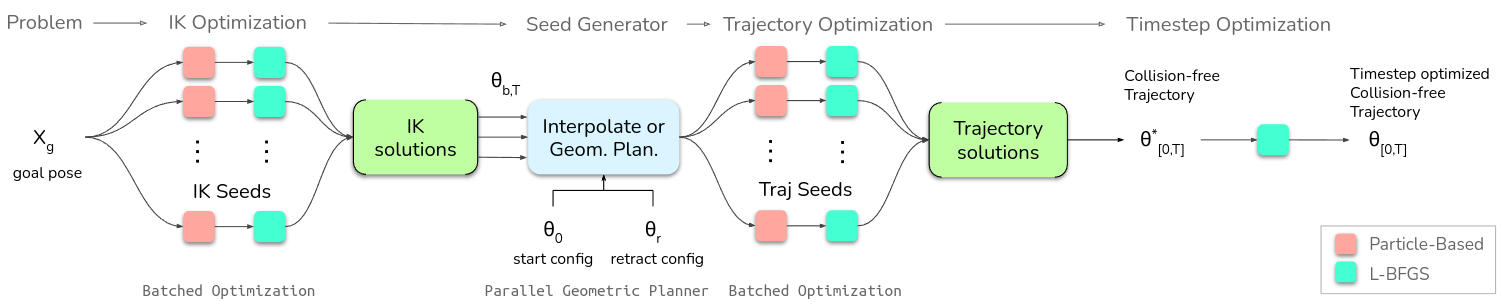
Motion Generation as Optimization
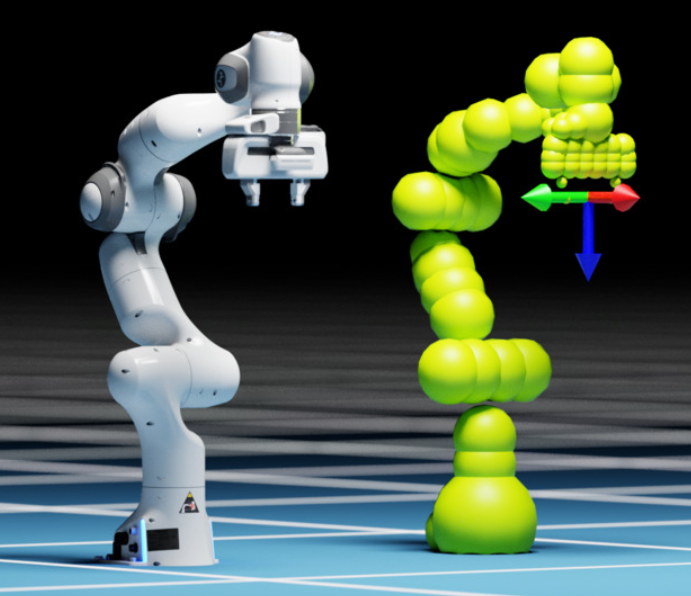
Kinematics & Collision Avoidane
- avoid colliding with itself (self-collision)
- avoid colliding with the world
world representation
- OBB
- Mesh
- Depth Camera
Parallel Optimization Solver
- particle-based optimization
- gradient-based optimization
N.B. To efficiently leverage GPU compute for motion generation, we found the following to be important:
- Reducing reads and writes to global memory to avoid hitting memory access latency.
- Skip writing zeros for gradients by keeping track of sparsity. As the optimization converges, most gradients will go to zero and skipping rewrites of zeros greatly reduces the memory access bottlenecks in our cost terms.
- Reducing number of kernels called in an optimization iteration by combining small kernels into a single larger kernel that does all the work from the small kernels.
- Using shared memory to share data across a thread block, enabling for-loops to be run in parallel.
- Leveraging warp-wide operations for computing values across small thread groups such as reductions and finding the maximum.