面向机器人学习的新型数据层
本文翻译自 Rerun 博客:A new data layer for robot learning(作者:Nikolaus West)。
物理 AI 将重塑整个物理世界的产业格局,但机器人领域至今仍缺乏支撑现代 AI 所需迭代速度的统一数据层(data layer)。核心挑战在于:机器人学习操作的是物理数据——多模态(multimodal)、多速率(multi-rate)的数据流,每一条都与时间、空间及具身形态(embodiment)紧密耦合。而现有的数据基础设施以 Web 数据为中心构建,难以应对上述特性。
在 Rerun,我们正在为物理数据构建一个统一的数据层,帮助团队训练并交付面向真实世界的智能系统。
Rerun 迄今规模最大的版本发布
Rerun 此前以其多模态时序数据可视化能力为人所知。在过去一年半中,团队一直在构建统一数据层的其他关键组件。0.32 版 Rerun SDK(GitHub Release)将这些能力以开源形式交付。
这是自 Rerun 三年前首次开源以来规模最大的版本,标志着 Rerun 可承担的工作范畴实现了重大扩展。新特性包括:文件格式稳定化、底层读写 API、chunk 操作 API、扩展的 MCAP 与 ROS 2 支持、数据集审查 UI、对磁盘上 .rrd 文件进行索引的开源目录服务器(catalog server),以及可直接在 .rrd 文件上训练的 PyTorch dataloader。
机器人生态系统长期缺乏一个足够灵活的统一框架来支撑机器人学习数据的完整生命周期。0.32 版本的出现,标志着这一基础架构正在成形。
与此同时,Rerun 还发布了 Rerun Hub(商业数据目录与存储引擎),目前已进入私有预览(private preview)阶段。它将 SDK 的能力扩展至对象存储(object storage)背面的数据集,为更大规模的数据提供共享目录与访问层。
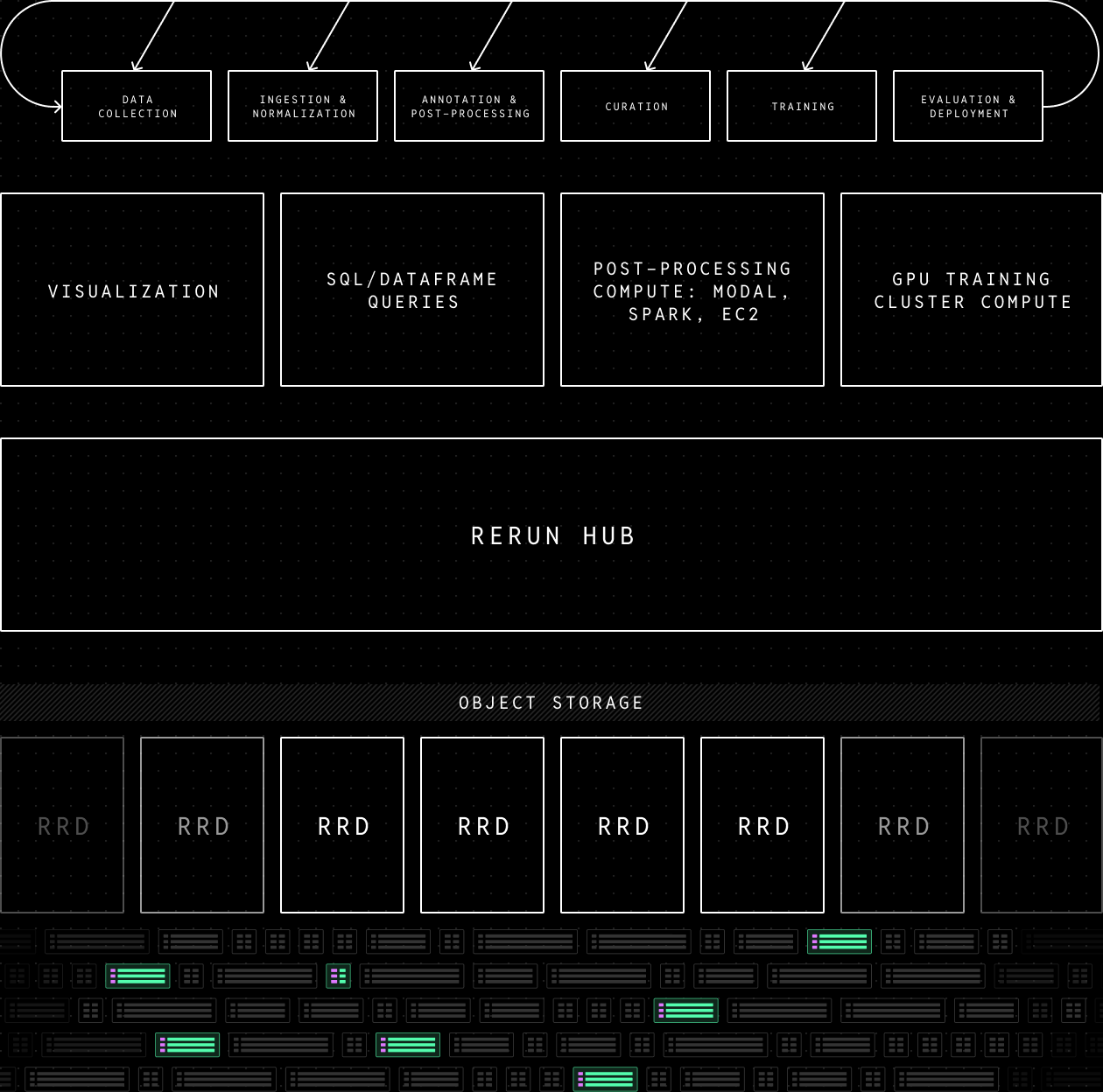
机器人学习需要专为物理数据构建的数据层
正如此前文章《The Data Layer Tax for Robot Learning》所述,大量摩擦源自强行将物理数据塞入为传统软件与分析负载设计的基础设施中。
编程智能体(Coding Agent)要求用户对计算层与应用层拥有完全控制权
团队在数据采集、归一化、后处理、数据筛选(curation)及训练等各环节均需要代码级控制。这正是 Rerun SDK 采取完全开源策略、并被设计为可嵌入构建流程的框架——而非封闭式 SaaS 平台——的原因。甚至连 Rerun 的 viewer 也以库(library)的形式提供。目前团队正在开发无头渲染(headless rendering)及面向智能体的 viewer 导航能力。
数据层必须处理大规模物理数据的核心难题
机器人学习工作流涵盖:数据采集 → 摄取与归一化 → 标注与后处理 → 数据筛选 → 训练 → 评估与部署。在该工作流之下,是由数据层支撑的计算与应用层(可视化、SQL/DataFrame 查询、Modal/Spark/EC2 上的后处理计算、GPU 训练集群计算)。
数据层所需的核心能力——可视化、分析查询、变换与训练——均须能够处理多速率、多模态数据,并理解三维空间关系与几何形态等机器人学语义。
数据层需要足够灵活,以同时满足上述所有核心应用与计算能力的需求。
物理数据的核心存储单元:列式 Chunk(Column Chunk)
物理数据具备两个区别于传统数据的特征:
- 多速率(Multi-rate):不同传感器以差异悬殊的频率记录数据(GPS 1–10 Hz、相机 10–30 Hz、关节角度 100–200 Hz、IMU 1 kHz);
- 多模态(Multimodal):不同传感器记录的数据量级差异极大(IMU/GPS 仅数字节,RGB 相机每帧可达数 MB)。
若采用传统行式表格存储(一行 = 一个时间戳,一列 = 一个数据流),将导致严重稀疏性与内存失衡。解决方案:将数据存储为 chunk,每个 chunk 持有行与列的子集。

- 高瘦 chunk:高频小数据(如 IMU)的多行窄列块;
- 短宽 chunk:单个大数据组件(如视频帧)的少量行宽列块。
在 Rerun 看来,列式 chunk 代表了机器人学习数据系统的最佳平衡点。
Rerun 的 .rrd 文件格式围绕列式 chunk 构建
.rrd 格式使用 Apache Arrow 的 record batch 作为底层数据容器,并附加语义元数据。每个 chunk 包含:header(chunk ID、实体路径、元数据)、row ID、时间列(time columns)以及一个或多个组件列(component columns)。
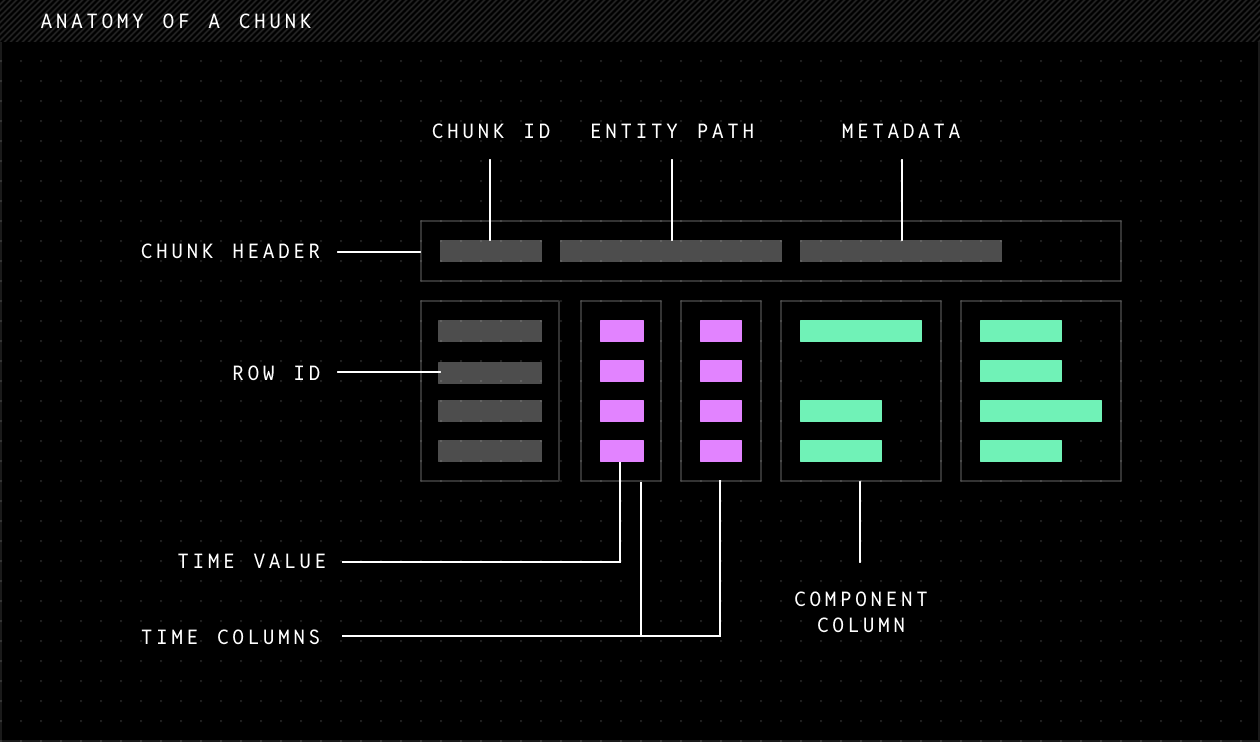
元数据中编码了语义解释信息(如”这是 IMU 传感器”“这是 GPS……”),使下游工具能够理解数据的物理含义。
列式 chunk 被封装为 protobuf 消息并顺序拼接。文件末尾的 footer 指向一个索引(index recordbatch),为每个 chunk 提供一条索引记录,从而实现快速随机访问。
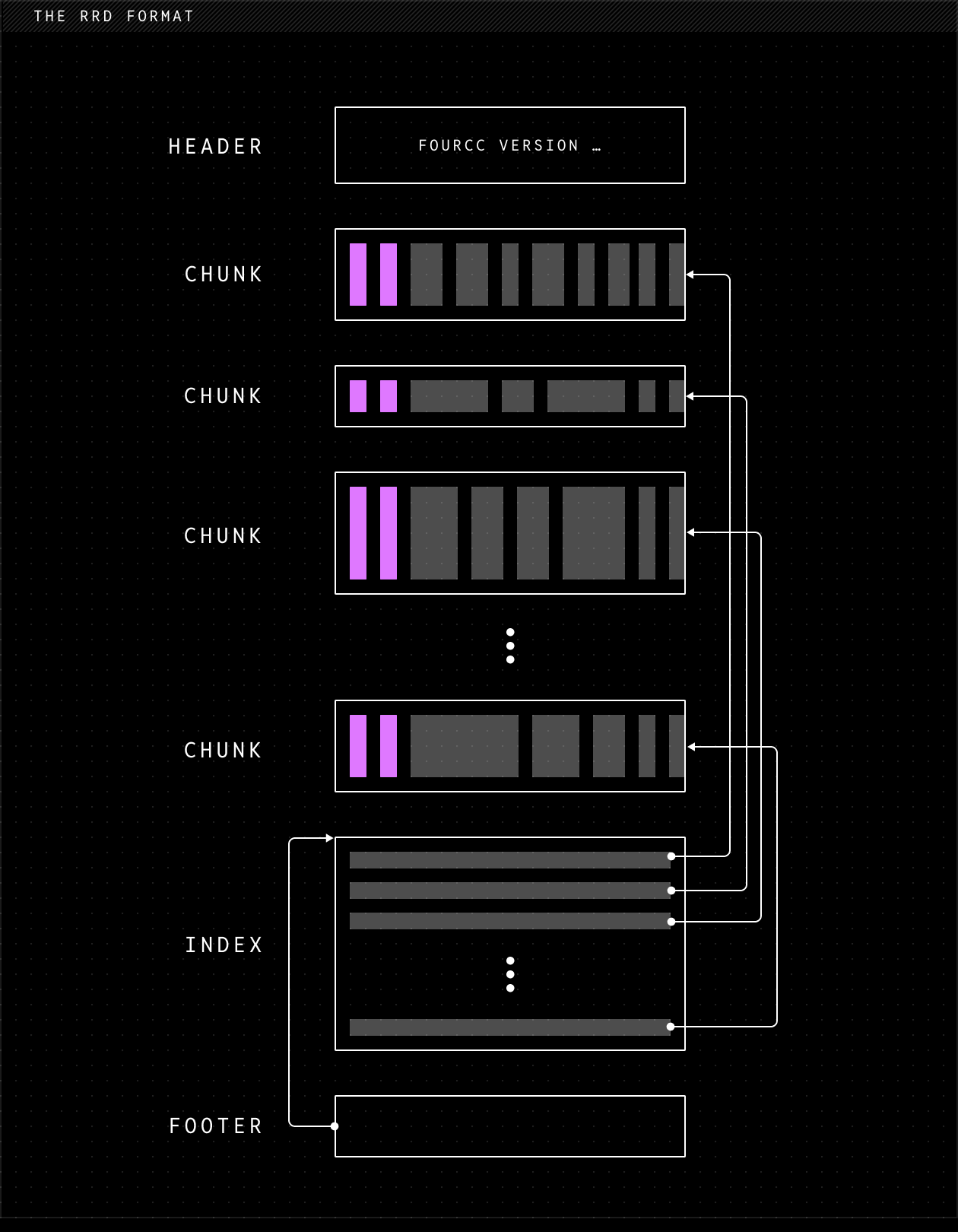
与其他格式的对比
| 格式 | 优势 | 局限 |
|---|---|---|
| Apache Parquet | 列式存储 | row group 不可重叠(所有列覆盖密集行范围),不适合多速率/多模态数据;不支持追加新列(缺乏 schema evolution) |
| MCAP | 面向机器人快速灵活写入,良好 ROS 兼容性 | 本质是不透明消息的容器,未针对列式分析查询优化;大批量扫描与 join 需逐条解码消息 |
| Lance | 面向多模态数据与随机访问,支持 schema evolution | 采用”行对齐片段的垂直堆叠”,多速率流会因 null 填充膨胀 |
| NCore(Nvidia) | 面向神经重建;通过逐组件时间戳实现多速率,通过位姿图实现空间对齐 | schema 封闭(仅限规范传感器组件);基于 Zarr 而非 Arrow 原生;未面向 SQL/DataFrame 查询引擎设计 |
Rerun 的格式能够在保留原始时间戳的前提下,实现从同一数据源进行查询、可视化及流式训练。
Chunk 之上的索引、Schema 与元数据层
逐 chunk 全扫描无法随规模扩展,因此需要元数据与索引层(即 data lakehouse 模式)。异构 chunk 不具备统一 schema,该层须跟踪各 chunk 的独立 schema 并按需物化合并后的 schema。
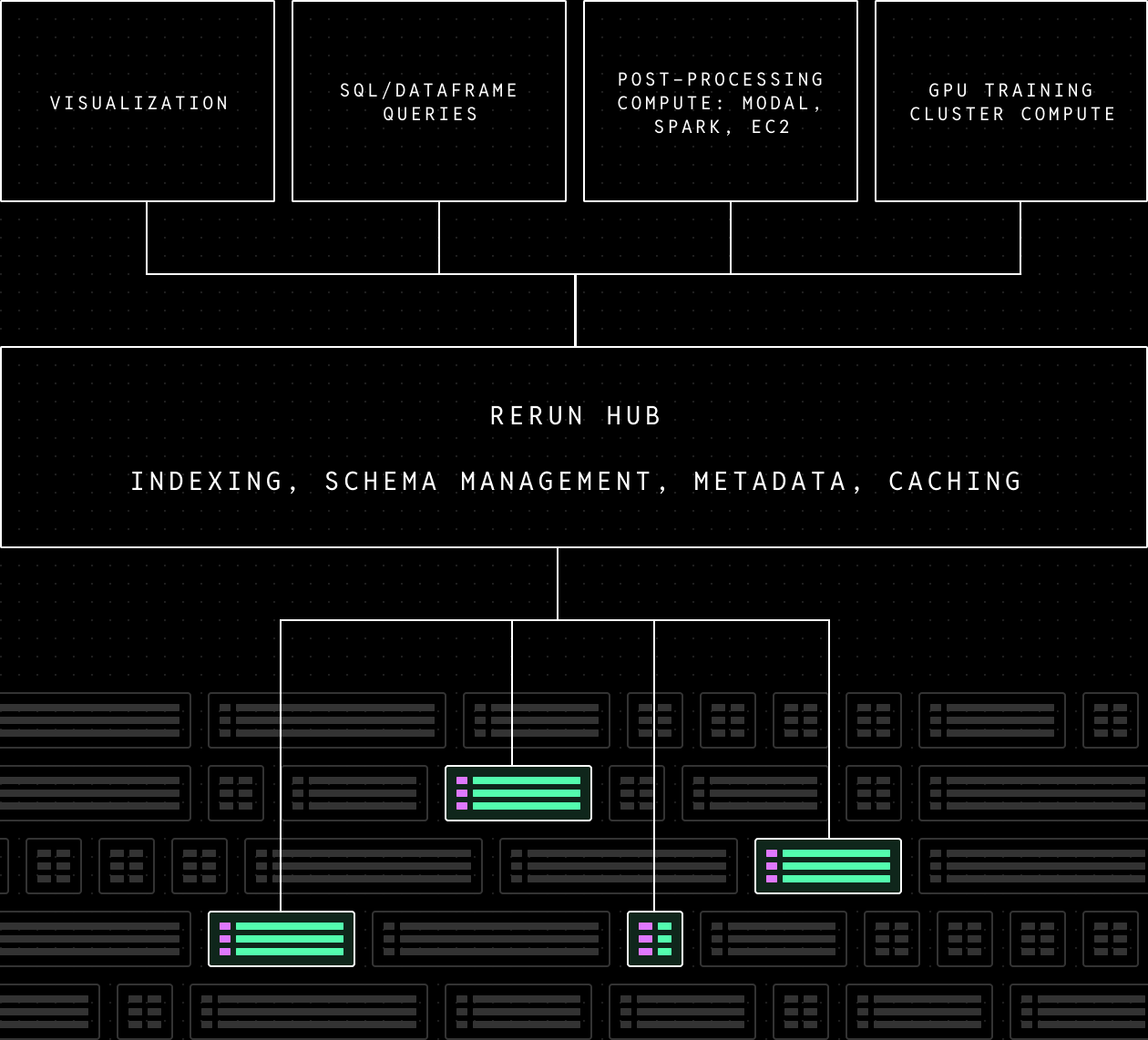
列式 chunk 配合高效索引,使您能够精确获取所需数据,而不必为无关数据流付出额外开销。
这一层抽象掉了底层文件概念,对外呈现为统一的 API。与机器人数据分离存储的标定数据也会被透明地处理。
大规模处理与训练需要从对象存储中进行选择性流式读取
机器人学习数据集的规模正迅速增长。为在大规模下高效处理,计算须靠近数据以减少延迟并最小化出口带宽成本。存储层则须与索引/元数据服务解耦。
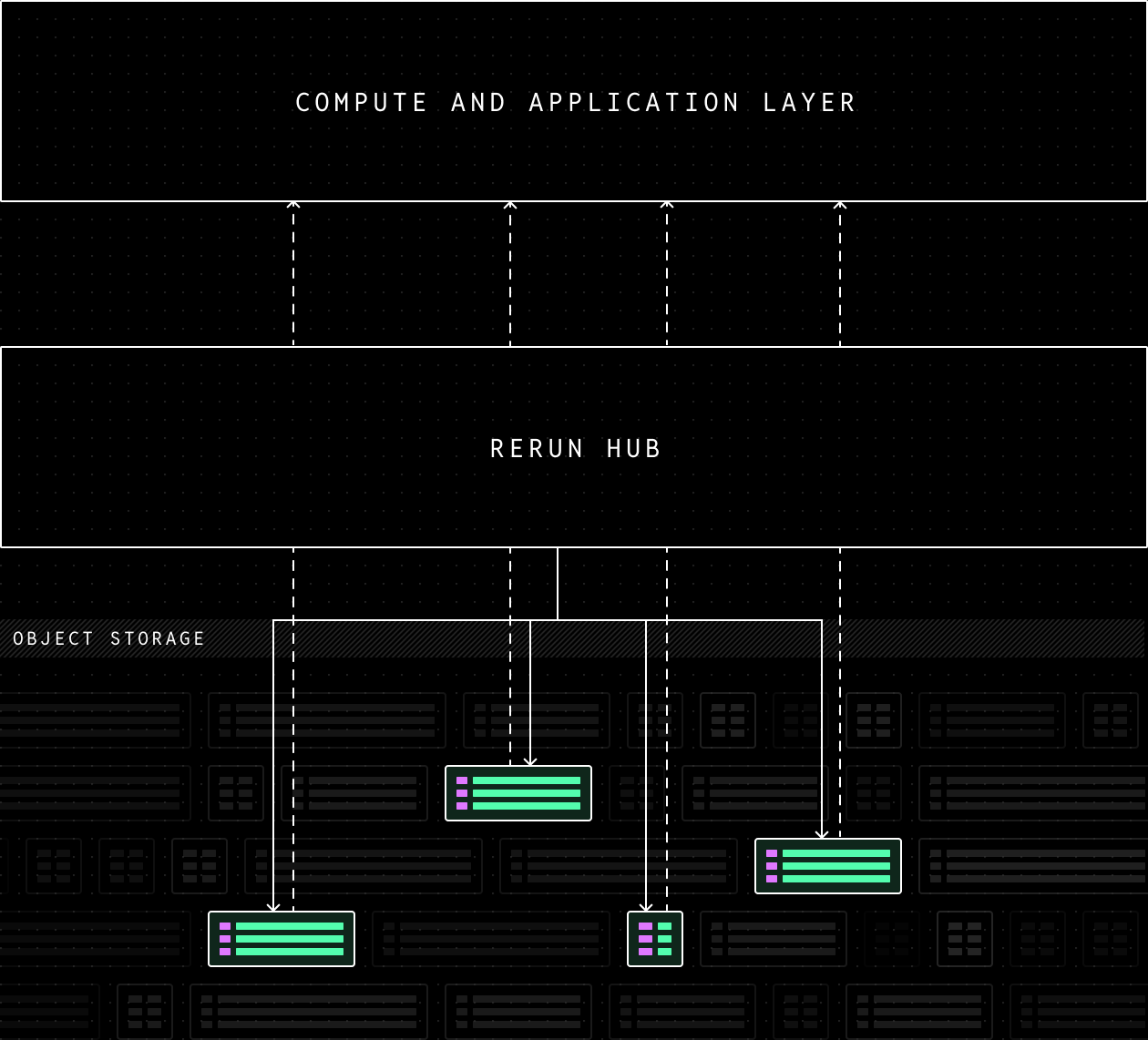
Rerun Hub 仅从对象存储中拉取每个作业所需的 chunk,使 CPU 或 GPU 计算可大规模并行展开,而无需迁移数据。
查询从 Rerun SDK 发起,经 Rerun Hub 路由——后者知晓哪些 chunk 与查询相关。SDK 随后通过缓存代理请求数据,或直接向对象存储请求指定字节范围。
Rerun SDK 0.32:面向机器人学习的统一数据工具包
0.32 版本将 Rerun 的能力从日志记录、可视化与简单查询,扩展至覆盖从数据采集到训练的完整数据链路。
稳定的文件格式与 chunk 级 Python API
.rrd 文件现已承诺向后兼容(自 0.23 起版本间兼容,现正式保证通用向后兼容性)。旧数据始终可加载。
0.32 之前,仅能通过导入器(importer)或高层 log/send_columns API 写入 .rrd 文件,读取则仅限于 DataFrame/SQL 查询。现在提供了 chunk 级的读写 API。
面向机器人数据整理的 Chunk 处理 API
新的(实验性)chunk 处理 API 为 .rrd、MCAP、Parquet、URDF 等格式提供了统一的加载器接口,输出 Apache Arrow chunk 流:
# 为每个数据源生成一个流,然后合并
## 包含大部分记录数据的 MCAP
mcap_stream = McapReader("my_file.mcap").stream()
## 包含静态资产的 URDF
scene_urdf = UrdfTree.from_file_path("scene.urdf", static_transform_entity_path="/tf_static/scene")
## 初始未捕获的两个机械臂之间的静态偏移
with json_path.open() as f:
transform = json.load(f)["transform"]
offset_chunk = Chunk.from_columns(
"/tf_static/robot_offsets",
columns=rr.Transform3D.columns(**transform)
)
robot_offsets_stream = LazyChunkStream.from_iter([offset_chunk]).stream()
merged_stream = LazyChunkStream.merge(
mcap_stream,
scene_urdf,
offset_chunk,
)
merged_stream.write_rrd()
同时发布了 Lenses——一种受 jq 启发的声明式语言,用于选择并变换深度嵌套结构体:
## 操作标准 IMU 消息
### 提取 x 分量并转换为 float32
mcap_stream = mcap_stream.lenses(
MutateLens(
"Imu:accel",
Selector(".x").pipe(lambda arr: pc.cast(arr, pa.float32())),
),
content=["/imu"]
)
这些 API 在设计上考虑了编程智能体(coding agent)的使用场景。未来,chunk 处理变换将可在 viewer 及云端(通过 Rerun Hub)运行。
扩展的 MCAP、ROS 2 类型支持与机器人可视化
0.32 版本为 MCAP 及常用 ROS 2 类型带来了性能提升和更多的即开即用支持,同时扩展了可视化能力:
- GridMap 原型及可视化器:用于在三维场景中渲染占用网格/二维地图;
- 状态时间线视图(State Timeline View,实验性):以分段着色条带在共享时间轴上可视化状态变化。
目录服务器:对本地磁盘上的多个录制文件进行索引化 SQL 或 DataFrame 查询
Catalog API 允许在机器人数据集上编写完全通用的 SQL 或 DataFrame 查询。0.32 中的开源目录服务器可对本地磁盘上的文件进行字节范围索引:
with rr.server.Server(datasets={"sample_dataset": directory_of_rrds}) as srv:
client = srv.client()
df = client.get_dataset("sample_dataset").reader(index="real_time")
# 统计第一个夹爪关节超过阈值的观测数量
df.filter(col("/action/gripper_position:Scalars:scalars")[0] > 0.5).count()
用于训练评估的快速数据集审查 UI
首个实验性数据集审查工具,支持浏览大量录制文件、发现异常、建立直觉及标记录制片段。通过标准的 Rerun blueprint 进行配置。
面向机器人学习的 DataLoader:数据集混合与 .rrd 随机访问
新的 rerun.experimental.dataloader 模块将 Rerun 录制文件暴露为可迭代(iterable)或映射式(map-style)PyTorch 数据集,支持编码图像、标量及压缩视频(h264/h265/av1)的直接流式读取。随机访问、多工作进程预取(prefetching)及 DDP 支持均即开即用:
source = DataSource(
dataset=client.get_dataset("my_robot_data"),
segments=[
"ILIAD_50aee79f_2023_07_12_20h_55m_08s",
"ILIAD_5e938e3b_2023_07_20_10h_40m_10s",
],
)
fields = {
"state": Field("/observation/joint_positions:Scalars:scalars", decode=NumericDecoder()),
"action": Field("/action/joint_positions:Scalars:scalars", decode=NumericDecoder()),
"Image.wrist": Field(
"/camera/wrist:VideoStream:sample",
decode=VideoFrameDecoder(codec="h264", keyframe_interval=500, fps_estimate=15.0),
),
}
ds = RerunIterableDataset(
source=source,
index="real_time",
fields=fields,
timeline_sampling=FixedRateSampling(rate_hz=15.0),
)
loader = DataLoader(ds, shuffle=False)
能够直接在用于可视化、分析与变换的同一数据层上进行训练,对于团队真正统一其数据基础设施至关重要。
Rerun Hub:面向规模化部署,现已开放私有预览
过去一年半中,Rerun 团队与早期初创公司和实验室共同构建数据层,目前已承载 PB 级机器人训练数据。Rerun Hub 是连接开源 SDK 的目录与存储引擎。数据可存储于任何兼容 S3 的对象存储中。Rerun Hub 协调从对象存储到 SDK 的直接选择性流式传输。集中式 hub 简化了协作流程,并提供可共享的数据链接。
私有预览申请:Rerun Hub Private Preview